
Not every business is fortunate to have an army of web developers at their disposal. For those businesses who are trying to implement search engine optimisation by themselves, technical SEO can seem extremely complex. In this article we aim to break down some of the less complicated tasks you can perform to audit your website and hopefully improve your website’s overall rank on search engines.
What is technical SEO?
Technical SEO is comprised of a series of processes used to help search engines find, read and understand your website. It mostly concerns the “behind-the-scenes” elements of your website and covers things such as meta data, indexing, linking, keywords and more.
Your website is built using various forms of coding, most often these are HTML, CSS and JavaScript. HTML dictates the structure of a web page, CSS controls how the page looks and JavaScript controls how that page acts (whether it’s interactive, if it’s got dynamic content, etc).
The goal with Technical SEO is to ensure there are no “road-blocks” that will stop search engines being able to read all of this correctly.
How do search engines “read” my website?
Search engines operate using three main processes; crawl, index and rank.
Crawl
Search engines deploy a team of robots (known as crawlers or spiders) to discover new content across the web. Content can vary in type and includes web pages, images and videos. They do this by using links which give the crawlers a path they can “crawl” to pick up anything that might’ve been added. You can encourage search engines to crawl your web pages at a more frequent rate by aiming to amplify your crawl budget.
Index
When these robots find new content, they add it to the search engine’s “index”, which is essentially a huge database of URLS that they’ve built up from crawling. When a user types in a search query, the search engine will then bring up the URLs it feels are most relevant to that search.
Rank
When a search query is entered, search engines want to display the most relevant content to the user. They use a series of signals to determine whether a website they have indexed should be shown on the results page.
The higher the website ranks the more relevant the search engine deems that website to be for the search query.
Most businesses want their websites to be ranking high on search engine results pages, as this leads to increased website traffic and, in turn, hopefully new leads and customers. However, if search engines can’t find or index their website, this is unlikely to happen.
Why is technical SEO important?
If you’re going through the process of optimising your website for search engines, you really don’t want to ignore technical SEO. You could have the most engaging website in the world, but if you’re not getting technical SEO right, you may not rank at all.
Because of its nature, Technical SEO can seem quite daunting, but doing a basic Technical SEO audit can highlight quick fixes and easy wins.
What is a technical SEO audit?
Consider a Technical SEO audit a kind of MOT for your website. When conducted by experts they can be in-depth and time-consuming, but there are a few key processes you can implement yourself to kickstart your search engine ascent.
Technical SEO auditing for beginners
Let’s look at some of the more basic technical issues that can have an impact on a website’s search ranking, these should be fixable without having a great deal of technical know-how.
Create an Organised Site Structure
Your site structure is how your site pages are organised. There needs to be a clear hierarchy to your website so that visitors can navigate your website and find what they are looking for with ease. If your visitors can successfully find their way around your website, then so can a crawler.
For instance, are your “about us” and “contact us” pages linked in the main navigation menu? Is your home page always accessible from other pages on your website? Whilst it’s tempting to forgo functionality in favour of design, you should always be considering how visitors will be using and interacting with your website. Your main menu should show a limited number of top-level, core pages to keep it clean and focused.
If your website is relatively small and you’re not selling a huge number of products on your website, a flat site structure would be the best option. This means that all pages are reachable within about 1 – 3 clicks. If a visitor can’t find what they’re looking for quickly, they may just exit your website in frustration and go elsewhere.
Having a flat website structure also means that Google and other search engines are able to crawl 100% of your website’s pages.
However, depending on the nature of your business, it’s not always possible to create a site this simple. For instance, if you’re a business that sells a large range of clothing from multiple brands, you’re going to have hundreds of pages that you need to organise, and the addition of “category” pages would be beneficial. When a website has more layers to it, it’s called a deep site structure.
With websites that require visitors to dig deeper to find what they need, you run the risk of disorientating them. This is where “breadcrumbs” are useful.
Breadcrumbs basically show a link for each level of the site from the homepage to the current page and look like this:

This helps visitors understand where they are on your website, and also find their way back to a previous page without having to start their journey again from the homepage.
When implementing a deep site structure, you also run the risk of creating problems for crawlers. You could end up creating orphan pages (pages that are not linked to from other pages on your site) or having pages that are no longer relevant to your site being displayed to visitors.
When implementing a more complex site structure, you should ensure that you are keeping on top of site maintenance.
Make sure the URL Structure is consistent
To further enhance your site structure, you should be considering the URL structure of your pages. When a visitor clicks a link, the URL displayed should be consistent with the page they land on. Don’t try to over-complicate it. If it’s confusing for visitors, chances are it’ll confuse crawlers too.
For instance, if you’re a florist selling roses, your URL for that page may look something like this; Florist.com/products/bouquets/roses
Rather than; Florist.com/products/product-10892
By organising your website into categories, you give the user the option to return to compare other options within the same category, without having to review options that are not relevant to them. Having this coherent URL structure also allows search engines to understand your website. Google likes to see how a page fits in to the structure of your website, by putting pages into categories you make this process easier.
Ensure your website can be indexed by search engines
Being indexed by search engines means your website will be able to appear in search results. Google can take anywhere between a few hours (for a single web page) and 6 months (for an entire website) to index content. There are a few things you can do to determine if your website has been indexed and to identify if there’s anything blocking search engines from doing so.
Monitor your index status
Once you’ve created your site pages you want to check that nothing is stopping Google from being able to index them.
You can use Google Search Console to run an Index Status Report to determine how many pages Google has crawled from your domain. The number of pages should increase overtime in line with your website growth.
Check your robots.txt file
A robots.txt file is plain text file that should be housed in the root directory of your domain (If you’re using WordPress it’ll be in the in the root directory of your WordPress installation). Its purpose is to tell search engine crawlers which of your site pages can or can’t be requested, however it’s not a way of keeping a web page out of Google.
By adding /robots.txt to the end of your website URL you’ll be able to view if any pages are being blocked from indexing that shouldn’t be.
If your site doesn’t have a robots.txt file the search crawler will go ahead and assume you want every page to be indexed which, for various reasons, might not always be the case.
If you’re adding a robots.txt file to your website you should make sure it’s definitely in plain text format and not a Microsoft Word or wordpad file, more advanced word processing programs can add invisible code to your file that can cause trouble for your website.
Search for your own website
Another way of seeing what pages have been indexed by Google is to search your site. By typing in ‘site:yourdomain.com’ into Google it will list your site’s indexed pages
Identify if noindex tags are being used.
Meta tags are a way of adding page-specific data and instructions to your html.
When creating a page, you can add a robots meta tag to instruct how that page should be indexed and shown to users in Google’s results pages. These tags are placed within the <head> section of a page and will usually look like this:
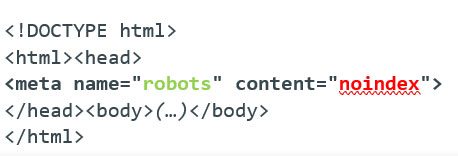
The noindex tag highlighted in red instructs search engines not to index that page when it crawls the website. The tag in green specifies that this instruction is to be carried out by all crawlers. There are additional tags that you can add which will inform specific crawlers. For instance, Google’s web crawler has the user-agent name Googlebot, so if you wanted to only instruct Google not to index your page, you’d replace “robots” with Googlebot.
If the noindex code is appearing in a page that you want to be indexed, you should remove the robots tag from the page completely, and when you’re confident your site has the correct use of this tag, (you may deliberately want to ‘noindex’ some pages) you should then resubmit a sitemap via the Google Search Console.
Refine your Meta data
Metadata is basically just data about data. Common metadata elements include page titles and descriptions, categories and page authors.
Metadata is added to the <head> section of your HTML file by using metatags and is good practice to have when it comes to improving your overall SEO efforts. There are many different tags that can be used, but here are some of the main ones you should focus on:
Title:
Whilst this isn’t strictly a metatag, it does appear in the <head> section and contains very important information; especially when it comes to SEO. Each page title should be unique, but also descriptive of the page in question.
Meta description:
This tag is used to add a description that will appear to searchers if your page appears on a search engine results page.
It doesn’t have any effect on ranking, but it is one of the most important elements of your web page as this description will basically be a deciding factor in whether a searcher clicks on your site or not.
Ideally meta descriptions should be snappy, yet able to hold the searcher’s attention, not an easy task when the description also should be kept to around 160 characters.
Viewport:
The viewport is the area of the webpage that is viewable for the user. On smaller, handheld and mobile devices the viewport will obviously be smaller than it is on a desktop screen.
This viewport tag signals to browsers that your page has been built to adapt to different screen sizes. Without this tag mobile browsers are likely to default to trying to display the page as if it were on a desktop, and then make their own decisions about font sizes and scaling of certain elements. When this happens, the users are likely to have to pinch and zoom to have any chance of using your site.
Leaving out the tag may also cause Google to judge your page as not being mobile friendly, which will harm your rankings, especially on searches carried out on a mobile device. With mobile friendliness playing such a huge part in SEO and website ranking, it’s a particularly good idea to include this tag.
It will look like this:
<meta name=”viewport” content=”width=device-width, initial-scale=1″>
This tag should really be included in all your web pages.
Robots:
If you want your page to be indexed then it’s really not a necessity to include this. If a robots meta tag isn’t found within the <head> sections, search engines will go ahead and take this to mean it can be indexed and the links in that page can be followed. However as mentioned earlier, the noindex tag can be added here to stop search engines indexing any pages you don’t want to appear in search results.
Page speed
Improving your page speed can directly affect your website’s rankings. Whilst it may not move you straight to the top of the search results pages, it can improve the overall user experience of your site, which is a big help. Luckily there are a few easy ways you can reduce page loading speed.
First off you should look at the actual size of the page itself. If you’re using images that are large and high resolution, you’re going to find that the page loads a lot slower. You should ensure that all images are scaled down and an appropriate site for web pages, remember; not everyone will be viewing your site will be using high-speed broadband. Some users will be relying on their mobile data coverage which, in some locations, can be a bit slow.
Ensuring any images used are quick to load, reduces the likelihood of frustrating the user.
You’ll also want to check and reduce your use of third-party scripts. Whilst some will be a necessity (Google Analytics, for instance), there may be others that you no longer need that are adding to your page load time for no reason.
Http vs Https: What’s the difference?
You may notice that when you land on a website’s homepage it will either display http:// or https:// at the start of the link in the URL bar.
The difference is that whilst http requests and responses are sent in plain text (meaning anyone could read them in theory), https uses TLS/SSL encryption when sending those requests/responses to create a level of security.
But why is this important to technical SEO? Well Google has said it favours sites using https:// so ideally you want to ensure your website is using it too.
Whilst the obtaining and installing of an SSL (Secure Socket Layer) certificate for your domain is a relatively simple process, you can even get a free SSL certificate from sites such as Let’s Encrypt and Cloudfare, depending on your specific setup there are things to watch out for.
Your rankings could be harmed for example if both the HTTP and HTTPS versions of your site URLS were available, and if you don’t use the correct redirection techniques to put all traffic on to HTTPS then you could be confusing the search engines. You would also need to be aware of how your sites canonical tag are configured (link to below) to ensure you don’t provide misinformation via these too.
In addition to this, your site’s use of third-party scripts or fonts loaded from external sources will also need to be done via HTTPS or you may end up with mixed content security warnings.
Wherever you get your SSL certificate from, it’s also important to know what the renewal process is and to keep on top of this. If an SSL certificate expires most browsers will display a warning page before the user gets to see your website, which is far from ideal.
Mobile Friendliness
With over half of all web traffic coming from mobiles it is paramount that your website renders correctly on mobile devices. Google updated its algorithm for mobile back in 2015 and since then mobile friendliness has been a key factor in how websites are ranked, especially in local search results.
A responsive design is recommended to ensure that your website visitors have an optimum experience regardless of the device they’re viewing your website on.
If you’re unsure how your website appears on mobile devices you can use Google’s mobile-friendly test to check.
The test results will include a screenshot of how the page looks on a mobile device, as well as listing any mobile usability errors it encounters, including things like small font sizes, incompatible plugins and use of Flash (which is often not supported by most mobile devices).
The test works on a page-by-page basis, so you’ll need to check each of your site’s major pages separately.
Structured Data
Structured data is a way of classifying information so that web crawlers can understand it. Whilst crawlers can “see” your content, they may not always understand the meaning of the content.
Using schema mark-up, you can tell search crawlers exactly what it is that they’re viewing and help them analyse your content in a more efficient manner. It’s a great way to organise content and label it in a way that search engines will have a clearer understanding of.
Schema mark-up can be embedded into web pages using the following:
- JSON-LD (preferred by Google)
- Microdata
- RDFa
By using structured data your website has a better chance at appearing in the richer features (aka rich snippets) on the search results pages. Features like recipe carousels or top stories, all appear at the top of Google’s results pages and appearing in one of these features is great for website visibility.
Google has a helpful guide containing more information on structured data and best practices surrounding it.
Avoid duplication of content
If Google detects content duplication on your website the authority of the page in question will be diminished and your search ranking will suffer, therefore it’s a good idea to address this issue sooner rather than later.
Often Google will suspect that duplicate content is created with the intent to trick search engines. If websites are targeting certain keywords, they may reproduce the same content across their pages in the hopes that they appear more relevant to search engines. However, this duplication of content will be of no use to a user with a genuine search query and will provide a poor user experience.
If you suspect that the content on your pages could be viewed as duplication you should rectify it immediately as Google can remove your site from their indexing completely, which could lead to your site not appearing in search results. If the duplication is necessary, you can utilise the canonical URL tag to lessen the confusion for crawlers.
What is a Canonical URL?
A canonical URL is the URL of the page that a search engine recognises as most representative from a set of duplicate pages on your site.
If you have multiple URLs pointing at the same page, or different pages with similar content (for instance, if your web page has a mobile and a desktop version), Google will pick one as the Canonical URL and crawl that. Google will see the others as duplicates, and they will be crawled less often.
You may not think you need to worry about this as you clearly don’t have any duplicate pages or URLs, but even your homepage could be problematic.
Can you reach your website homepage by the following links?
• http://www.yourdomain.com
• https://www.yourdomain.com
• http://yourdomain.com
• http://yourdomain.com/index.php
• http://yourdomain.com/index.php?r…
You may think that all these URLs are representative of a single page, but to a search crawler, these links represent individual pages, so it essentially sees five home pages when it’s trying to crawl your site.
This is where the canonical tag comes in useful. The Canonical Tag is a way for you to tell Google which URL/page is the one you would like to be indexed.
It will appear in the page’s HTML as <link rel=”canonical” href=”https://yourdomain.co.uk/”> and can be self-referencing (I.e, you can have the tag pointing to the page its set on)

The Localiq.co.uk website has a self-referential tag.
Remove low value pages
Every page of your website should have a purpose and provide valuable, relevant content for site visitors. After spending so much time trying to get search engines to index your website you may wonder why you’d ever want to de-index them.
Campaign landing pages
Often businesses will create a separate landing page if they’re running a time-specific marketing campaign, usually they contain a gated resource that requires visitors to submit some basic information in order to access a download. If a visitor lands on one of these through an organic search and not through the intended channels, it may skew the campaign’s results.
Not de-indexing these types of pages could also mean that a searcher lands on the campaign’s “thank you” page, which in some instances may mean they can download the gated resource without having to part with that information. Again, this would potentially skew the results of the campaign too.
By adding a no-index tag to these pages, you ensure that any paid-for marketing campaigns are not jeopardised by organic searches and that searchers click on a page that is likely to be more relevant to their query.
Time-sensitive content
You should also remove or de-index any web pages that are no longer being used. Simply removing a webpage from your site’s navigation won’t be enough, as it will still be indexed by search engines.
Whilst the above is not an exhaustive list of everything you need to consider for technical SEO, they are things that will help improve your site’s health. If you’re looking for more information on technical SEO, we’d be happy to help.


